
Insights 13 min read
The power of Edge AI Inferencing
Edge AI inference cuts latency, cost, and energy waste. WATTER turns compute heat into usable power for smarter, more efficient infrastructure.

AI has outgrown the limits of centralized infrastructure. As inferencing workloads multiply, sending data back and forth to the cloud is no longer efficient—or sustainable. The Power of Edge AI Inferencing explores how bringing compute closer to where data is created unlocks new levels of performance, resilience, and energy efficiency.
The Edge Is No Longer Optional
AI has escaped the lab. Many industries were experimenting with AI models by training and testing them against different use cases to solve problems. The problems solved included detecting anomalies in production lines, understanding and predicting supply chain bottlenecks, and scanning video feeds to detect unusual patterns, among others. What used to be in R&D labs has now become operational in the real world, serving many customers who are realizing immense value from these AI solutions. The AI models supporting these solutions are both trained and deployed on the cloud for inferencing. However, the key question to answer is whether some solutions can achieve greater value if the inferencing is shifted closer to where the data is being produced?
The closer the inferencing happens to where the data is generated, the greater the benefit. When AI models can process information on site—within the same facility or network where sensors, cameras, and systems generate that data—they respond faster, operate more securely, and cost less to run. Latency drops from hundreds of milliseconds to near real-time, while bandwidth usage and cloud egress fees decline. Sensitive information, whether from manufacturing lines, hospitals, or financial systems, can stay within the organization’s perimeter instead of moving back and forth across the internet. These operational and security advantages are now reshaping the economics of AI itself. AI inferencing workloads already make up the majority of enterprise AI spending, growing nearly 20 percent per year. The center of gravity for compute is shifting toward the edge—closer to where data is created and decisions are made.
Edge computing is scaling at historic speed. Analysts project a $250–400 billion market by 2030, with the majority of enterprise data processed outside traditional data centers. The reason is simple: when milliseconds matter, distance becomes a cost. For video analytics, IoT, and safety systems, local inferencing cuts response time from 100 milliseconds to under 10. It also trims cloud egress fees, reduces exposure to outages, and keeps regulated information (patient scans, financial records, production data) within secure walls.
At WATTER, our focus is to enable AI inferencing at the edge. We are building a hyperscale distributed cloud platform that co-exists and supports the Mechanical (Core) Infrastructure we find in buildings today - The water heater. Each unit performs high-intensity inferencing while recycling its waste heat to produce hot water. It’s a simple idea with powerful implications: the data you process can literally heat your building. For facilities that already depend on continuous hot-water demand, onsite inferencing transforms a passive asset into an intelligent one.
As inferencing becomes the default mode of AI, enterprises are rethinking where their compute belongs. The edge is not a niche anymore. It’s the next frontier of performance, privacy, and efficiency, and it’s already being installed in basements, boiler rooms, and mechanical closets across Texas.
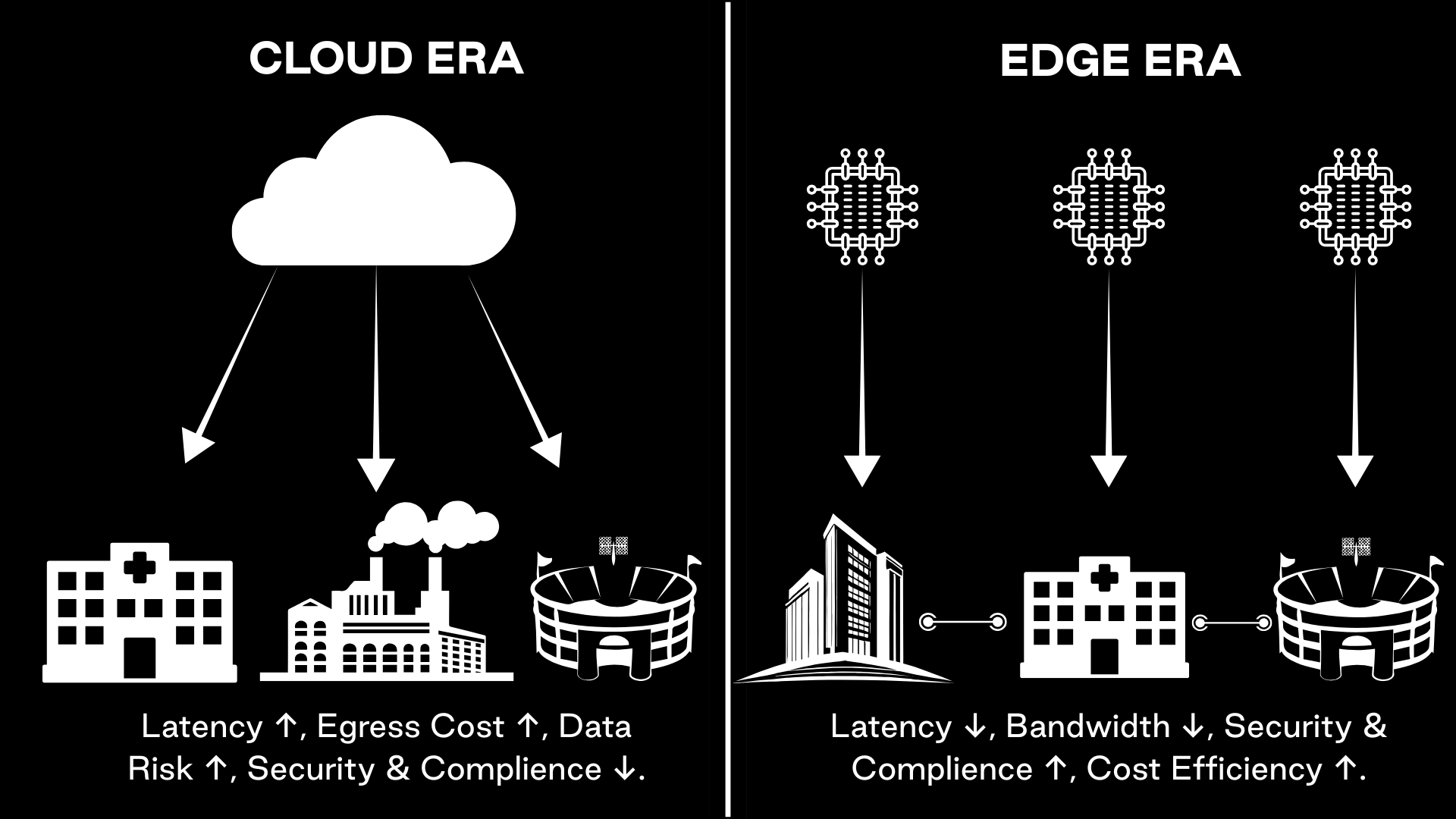 Inferencing is moving closer to where data is created — faster, cheaper, and more secure.
Inferencing is moving closer to where data is created — faster, cheaper, and more secure.
Why Edge Inferencing Matters Now
AI’s impact is no longer limited by model accuracy. It’s limited by physics, cost, and control. Every second that data travels across networks adds latency, risk, and expense. And this isn’t just about computer vision anymore. With the rise of generative AI and large language models (LLMs) powering decision support, customer interactions, and intelligent automation, AI inferencing workloads have exploded. As enterprises deploy these models at scale, the economics and reliability of cloud-only inferencing are starting to break down.
Latency and performance remain the first pressure points. A video-analytics system running in the cloud can take 80–150 milliseconds to process a frame. At the edge, that drops below 10. That gap can mean detecting an anomaly in a production line before equipment fails, or missing it entirely. For LLM-powered decision systems, it’s the difference between instant recommendations and frustrating pauses that kill user trust. For workloads that demand real-time responsiveness, AI inferencing must live where the data is generated.
Cost control follows quickly behind. Inferencing is about compute and movement. Every time a sensor or application sends raw data to the cloud for inferencing, and the resulting decision or control signal comes back, organizations pay bandwidth and egress fees. For example, a factory running a vision-based safety system might stream hundreds of camera feeds to the cloud every second. The inferencing results (“stop line,” “pause conveyor,” “alert operator”) must then be transmitted back. That two-way flow compounds cost. In some cases, up to 30% of AI infrastructure spend is lost to data egress and network overhead. Running inference locally avoids that entire loop, slashing ongoing expenses and improving predictability in compute costs.
Data privacy, security, and sovereignty have become equally decisive. Hospitals, banks, and logistics firms operate under strict data-handling requirements. Sending sensitive patient imagery, transaction data, or security video to public clouds increases exposure and regulatory risk. Local inferencing keeps sensitive data within the organization’s perimeter, allowing teams to apply their own security controls and reduce exposure to breaches or compliance violations.
Finally, resilience is being redefined. Dependence on centralized cloud vendors means every outage, upgrade, or API change can ripple through critical systems. When customers own the hardware, debugging and optimization happen in-house — with no waiting for external support tickets or service restoration. Edge inferencing provides greater control, faster recovery, and more predictable uptime when it matters most. At WATTER, we believe these challenges with the cloud present an opportunity to think differently — and to help reduce the load on centralized hyperscale data centers. By embedding compute directly inside hot-water infrastructure, WATTER brings inferencing physically closer to the sources of data , delivering faster performance, tighter security, lower cost, and higher resilience. And by reusing the heat that computation generates, we add an entirely new layer of value — turning what was once wasted energy into measurable operational and sustainability gains.
The Missed Opportunity — Waste Heat
Every GPU cycle turns electricity into two things: computation and heat. In most data centers, that heat is treated as waste — something to be cooled away at enormous cost. Yet the same energy that powers AI workloads can offset one of the largest thermal loads in commercial buildings: hot water.
Research shows that servers release between 85% and 95% of their consumed electrical energy as heat, much of it at temperatures usable for low- to medium-grade applications such as water or space heating. Around the world, major data centers have already begun recovering that energy rather than dissipating it:
-
Meta’s Odense data center in Denmark supplies district heating for roughly 11,000 homes, cutting CO₂ emissions by more than 25,000 tons per year.
-
AWS in Sweden channels waste heat from its facilities into local district networks, warming more than 20,000 households.
-
IBM Zurich’s system reuses about 30% of server energy for on-site heating through a closed-loop exchanger.
The parallel for commercial buildings is immediate. In hotels, hospitals, and food-processing plants, water heating accounts for about 20% of total energy use — a figure consistent across U.S. Department of Energy and hospitality-sector studies. Offsetting even half of that demand through recovered compute heat can save thousands of dollars monthly while producing verifiable emissions reductions for ESG reporting.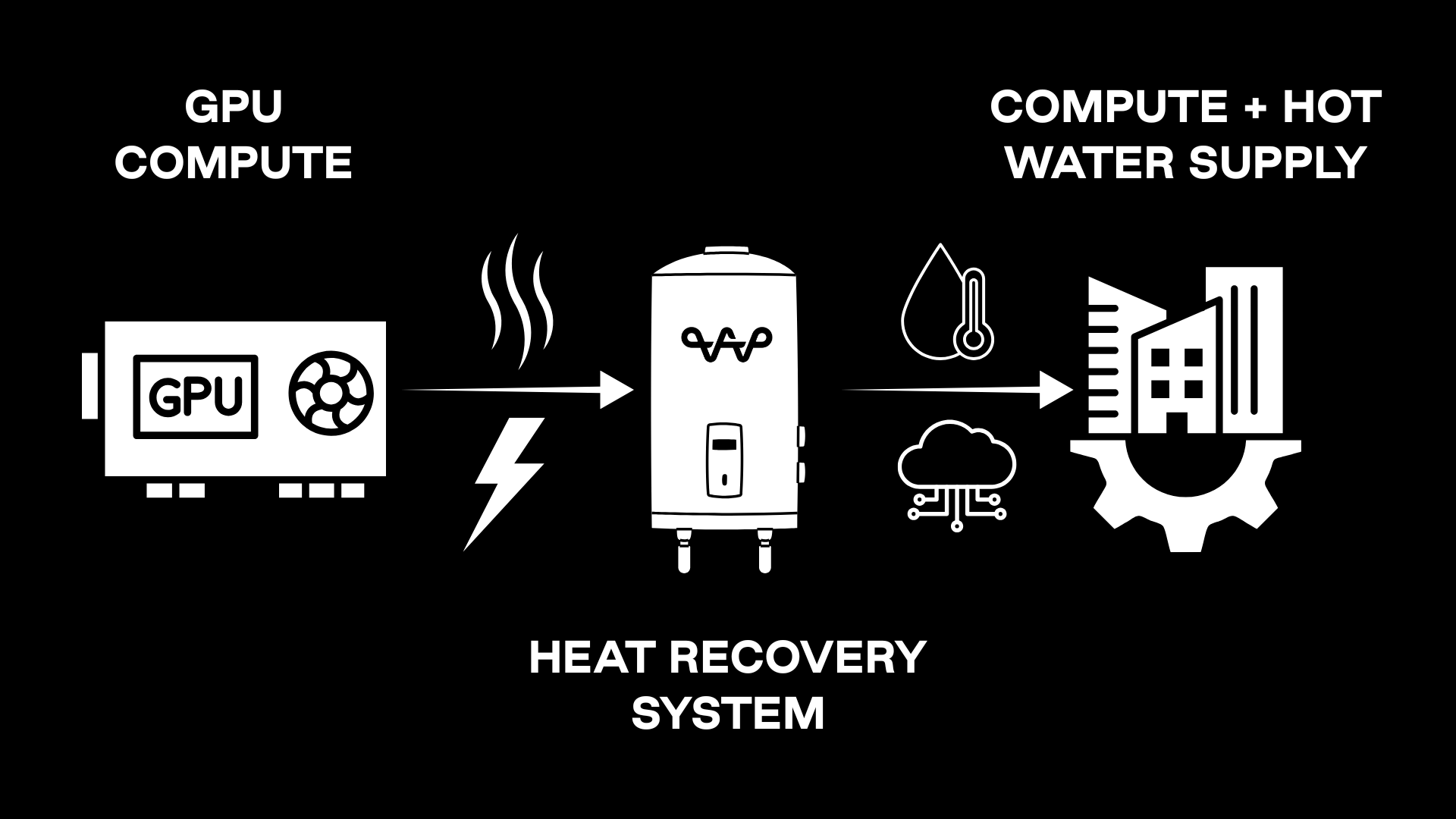 Every watt of computation does double duty — powering AI and heating the building. Energy Saved, CO₂ Reduced, Operational Cost ↓, Revenue ↑
Every watt of computation does double duty — powering AI and heating the building. Energy Saved, CO₂ Reduced, Operational Cost ↓, Revenue ↑
This is exactly the opportunity WATTER captures by design. Each WATTER unit performs high-intensity inferencing while routing recovered heat into the building’s existing hot-water loop. Instead of exhausting energy into the atmosphere, the system converts every watt of computation into a dual return: digital work and thermal utility.
For commercial property owners, that dual return translates into tangible financial benefits. By offsetting a significant portion of their water-heating costs, facilities lower one of their most persistent utility expenses. At the same time, hosting inferencing workloads opens the door to a new revenue stream — effectively getting paid to heat water. Each installation turns a mechanical necessity into an active asset that improves margins, strengthens ESG performance, and turns infrastructure into a profit center, contributing to both the top and bottom line.
For enterprises balancing AI growth with sustainability mandates, this closed-loop model reframes efficiency itself as a new layer of infrastructure performance. Where traditional systems see waste, WATTER sees value ready to be recirculated.
Case-Style Examples — Where Onsite Inferencing Wins
The advantages of onsite inferencing are easiest to see when translated into familiar operational settings. Across sectors, facilities are already discovering that local compute is faster, safer, cheaper, and more resilient.
1. Stadium Security and Real-Time Video Analytics
Large venues depend on continuous video surveillance to manage safety and crowd flow. Processing that data in the cloud creates latency gaps that can delay detection by seconds. Studies show that edge-based video analytics reduce response times from over 100 ms in the cloud to under 10 ms locally.
In one reference deployment, an arena using edge AI for crowd monitoring achieved real-time incident alerts while cutting data-transfer costs by more than 40 %.
For facilities like Dickies Arena or AT&T Stadium in Texas, where uptime, safety, and fan experience converge, local inferencing eliminates the lag that centralized systems can’t avoid.
2. Real-Time Operations and Intelligent Infrastructure
In environments where people and systems move continuously — airports, logistics hubs, or large campus facilities — even small delays in data processing can disrupt operations. On-site AI inferencing enables instant decision-making where it matters most: at the network’s edge.
Take an airport operations center as an example. Vision models track passenger queues, gate traffic, and baggage flow to predict congestion and trigger responses automatically. When this inferencing runs in the cloud, insights can arrive seconds too late to act. Running inference locally, within the airport’s own IT network, cuts latency from hundreds of milliseconds to under ten, allowing systems to respond in real time — adjusting staffing, routing, or gate assignments before issues cascade.
The same applies to distributed environments such as cafeterias or retail chains using AI for demand forecasting, inventory monitoring, or food-safety compliance. Local inferencing allows these systems to detect anomalies instantly and act without sending sensitive operational data off-site.
For IT infrastructure leaders responsible for deploying and securing these systems, local compute provides faster analytics, stronger data governance, and more predictable performance. It reduces dependence on hyperscale vendors and gives enterprise teams direct visibility and control over their own inferencing environments — improving uptime, responsiveness, and security all at once.
3. Manufacturing and Food Processing Quality Control
In industrial environments, inferencing must happen as close to the production line as possible. Research shows that edge-AI quality-control systems can detect product anomalies in milliseconds, preventing costly waste and downtime.
Food and beverage facilities, such as bottling plants, also have continuous hot-water requirements for cleaning and sterilization — making them natural candidates for WATTER’s dual model.
Each WATTER node performs compute tasks (e.g., vision-based inspection) while its heat output feeds the plant’s water-heating system. The result: lower latency, lower defects, and a direct offset in energy cost.
Across these examples, the pattern is the same: when compute happens closer to where value is created, performance improves and cost drops. WATTER turns that technical principle into a physical one: pairing the compute power needed for real-time AI with the thermal demand every facility already has.
The Broader Impact — Compute That Pays for Itself
For enterprise infrastructure teams, the case for onsite inferencing is about performance, economics, and accountability. Cloud GPUs remain indispensable, but their costs, carbon intensity, and spatial demands have become increasingly difficult to justify. Traditional data centers consume vast real estate, specialized cooling, and dedicated grid capacity — all to support workloads that, in many cases, could run within the infrastructure organizations already have.
Local inferencing flips that model. It delivers the same computational power without the footprint, plugging directly into existing facilities instead of building new ones. By using what’s already there — mechanical rooms, water systems, and thermal loops — onsite inferencing eliminates redundant infrastructure while paying itself back through efficiency gains, reduced transmission overhead, and verifiable sustainability impact.
The Economics of Location
Moving workloads closer to where data originates cuts a double line item: bandwidth fees and energy waste. Industry analyses show that edge deployments can reduce total operating costs by 30–40 percent through lower egress charges and shorter data-transfer paths.
Because inferencing workloads dominate AI usage (now consuming most of the sector’s energy draw), every percentage improvement in efficiency compounds quickly.
From Green Claims to Real Physics
The sustainability story of compute has often been written in credits, not in kilowatt-hours. Hyperscalers claim “carbon neutrality” by purchasing renewable energy offsets that rarely align with when or where their servers actually run. Local inferencing changes that equation. Researchers comparing cloud and edge operations note that cloud data centers can emit 30–50 percent more CO₂ per kWh than regionally balanced edge nodes when measured on a location basis.
By placing compute inside existing facilities, the energy that powers AI workloads also provides usable heat — doing two jobs instead of one. Each watt contributes to both digital processing and a building’s thermal needs, creating measurable reductions in real energy consumption and emissions. This is sustainability grounded in physics, not paperwork: visible, quantifiable, and verifiable at the site level.
A Measurable ESG Advantage
Current sustainability frameworks such as CDP and GRI now expect enterprises to report real, physics-based reductions rather than offsets.
For infrastructure and sustainability leads, this makes edge inferencing an operational lever: a way to shrink emissions profiles without slowing digital growth. Each onsite node becomes a micro-data-center whose energy output directly supports facility utilities, an efficiency that auditors can measure in kWh and CO₂, not just in certificates purchased.
The Emerging Model
As distributed networks expand, this model of “compute that pays for itself” is scaling beyond early adopters. Analysts project that edge infrastructure investments will exceed $400 billion by 2030, capturing the majority of new enterprise workloads.
For CIOs and heads of infrastructure, that trajectory points to a practical future: a hybrid estate where hyperscale capacity handles training and global reach, while local inferencing nodes deliver real-time performance, lower costs, and verifiable sustainability.
The Infrastructure Advantage — Why Now?
Enterprise infrastructure has reached an inflection point. For years, scale equaled centralization: ever-larger data centers, ever-longer network paths. But the physics and economics of AI inferencing are reversing that logic. The next decade of compute growth will come not from expanding clouds, but from distributing intelligence into the infrastructure that already exists.
Timing and Technology Alignment
Hardware, software, and sustainability forces are aligning to make onsite inferencing both possible and necessary. Together, they mark a structural shift in how enterprise infrastructure will be designed and operated in the decade ahead.
-
Hardware maturity. Energy-efficient GPUs and containerized workloads now make small-footprint, high-performance inferencing practical anywhere. Edge hardware performance per watt has improved by more than 30 percent in just two years.
-
Software orchestration. The rise of cloud-native tools has made distributed compute not only possible but reliable at scale. Technologies such as Kubernetes, container orchestration frameworks, and distributed storage systems allow workloads to move fluidly between central and local nodes. These advances enable a new kind of hybrid architecture: a logical cloud that spans multiple physical locations, where inferencing can run wherever it performs best.
-
Network strain. Inferencing demand already dominates AI traffic, and cloud egress fees keep climbing. Processing data where it originates eliminates much of that cost.
-
Regulatory and ESG pressure. New reporting frameworks under CDP and GRI favor location-based energy accounting, which rewards infrastructure that physically reduces consumption rather than offsetting it.
Economic Momentum
Market forecasts show this transition accelerating. Edge infrastructure investment is projected to exceed $400 billion by 2030, representing the majority of new enterprise workloads. For CIOs and heads of infrastructure, the implication is clear: those who design hybrid architectures now, pairing centralized training with local inferencing, will own the performance and cost curve over the next cycle.
WATTER’s role in this new paradigm
What makes WATTER’s model distinct is timing. It enters precisely as compute density meets facility readiness. By embedding GPUs inside equipment that already consumes and manages heat, WATTER eliminates the final inefficiency: waste. Each installation becomes both a node in a distributed compute fabric and an upgrade to the building’s mechanical system. That dual purpose turns infrastructure from a liability into an active asset.
A Call to Infrastructure and Platform Leaders
For infrastructure and platform leaders, the choice is no longer between cloud vs. on-prem. It’s between centralized cost and distributed value. Local inferencing isn’t an experiment; it’s a performance layer that pays for itself. Those who adopt it early will not only reduce latency and energy spend but also build the blueprint for the next generation of sustainable compute architecture.
Explore What Local Compute Can Do for You
If you’re leading an infrastructure, platform, or data engineering team and want to see how onsite inferencing could reshape your performance and cost profile, connect with WATTER’s team. Early access programs in Texas are helping enterprises test real workloads and measure the dual impact: faster compute, lower energy spend.
Request an Advisory Session at WATTER.com.
Next Step
Bring WATTER to your facility.
Turn hot-water demand into compute revenue, or reserve early access for residential.
Keep Reading
More from WATTER

The Decarbonization & Cost Advantage Inside Your Boiler Room
Discover how WATTER turns AI workloads into usable heat, reducing emissions and energy costs while helping buildings achieve real, measurable ESG progress.

How Green Compute Can Save the Environment, Money, and Keep Your Company Safe
Explore how distributed compute and heat reuse improve PUE, lower emissions, and enhance resilience. Watter’s approach delivers scalable AI inference while reducing energy waste in commercial and residential properties.

The Startup Edge: Why Local, Green Compute is the Next Advantage
Discover why energy—not chips—is the real AI bottleneck and how Watter’s smart water‐heater solution reclaims waste heat to power distributed AI, cut emissions, and unlock new revenue streams.